|
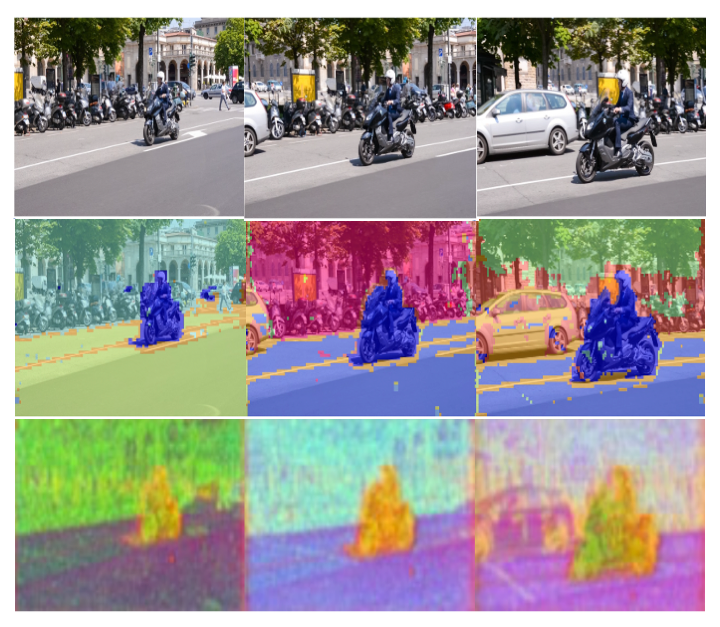
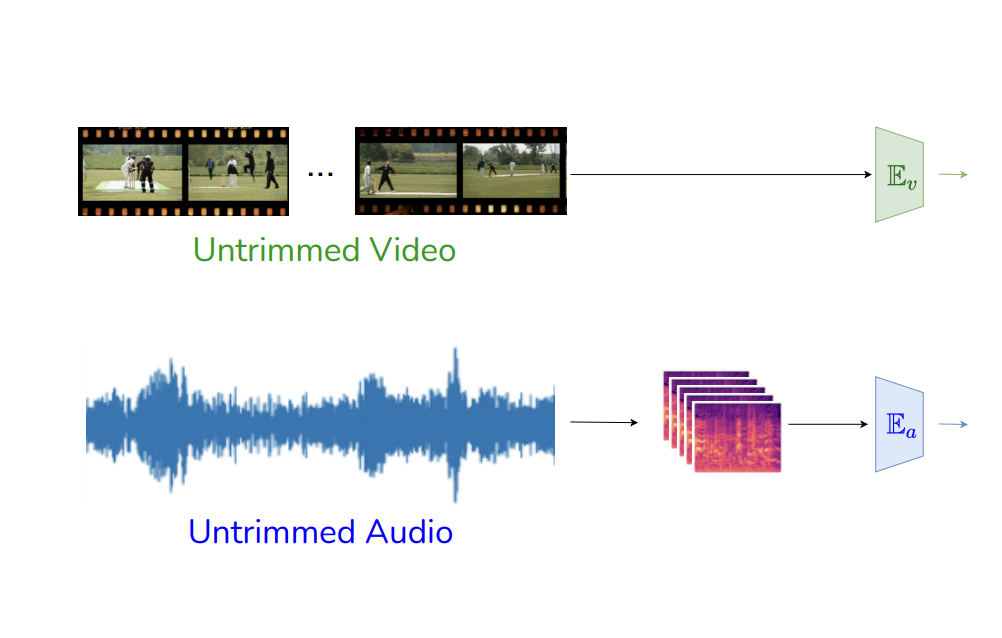
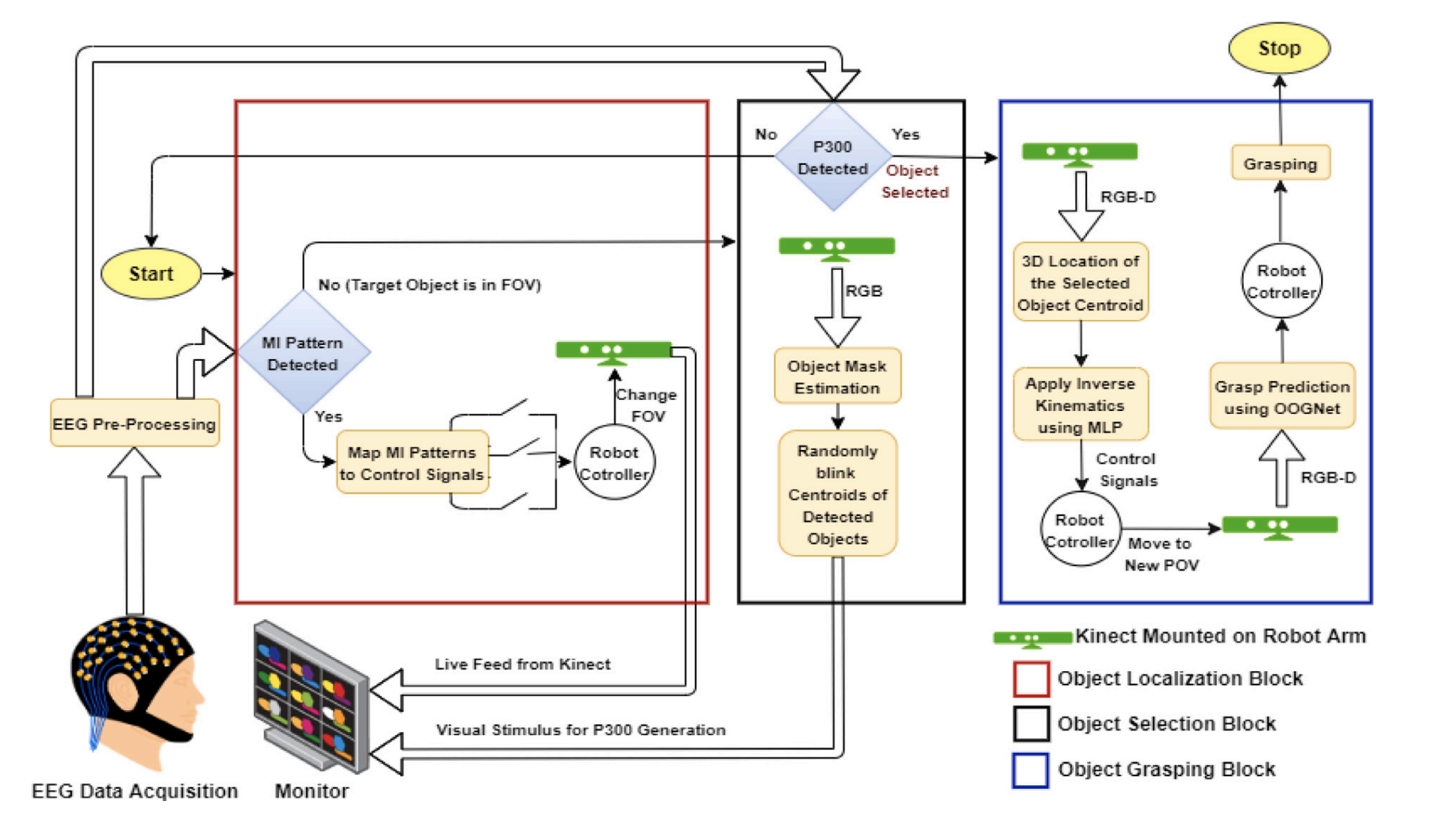
Anurag Bagchi Hello! I am a Research Associate III in the Robotics Institute at Carnegie Mellon University, where I work on Video Diffusion Models for Multi-Modal Robot Perception, under the supervision of Prof. Martial Hebert. I also collaborate closely with Dr. Pavel Tokmakov at Toyota Research Institute and Prof. Yuxiong Wang at UIUC. Before this, I worked as a Computer Vision Engineer in Prof. Song Bai's team at Bytedance AI Lab Singapore, where I developed Multi-modal (Vision, language and Audio) models for TikTok's Brand Safety Policies. Prior to that, I was fortunate to be among the youngest Machine Learning Engineers to join the stellar Recommendation Team at TikTok R&D Singapore, where I built end-to-end ML systems for TikTok's Video & Push Recommendation. During this period I also collaborated closely with Prof. Ravi Kiran and Prof. Makarand Tapaswi in the Computer Vision group at IIIT Hyderabad, working on Temporal Action Localisation in Videos. I received my Bachelor's Degree in Electronics and Tele-Communication Engineering from Jadavpur University, India where I worked under Prof. Amit Konar at the intersection of Computer Vision & BCI. During my years as an undergrad, I spent a wonderful summer in the Imaging R&D team at Samsung Research, leveraging ToF Depth data for Samsung's camera applications. |

|
Research |